Serverless Java with AWS Lambda: Introduction
Just as we are over the crest of the microservice hype and can finally see how this architectural tool might (or might not) solve our problems the next hype is already here: serverless programming! In this first blog post I’m going to explain what serverless is, what it isn’t, and how it can change the way we create software. In the next posts I’m going to show a few simple examples using a well known 'serverless' platform: AWS Lambda. Originally posted here .
Introduction
So what is serverless? It’s not uncommon to see developers joke about how silly the term is because there’s obviously still a server right? Of course there is. It’s impossible to run software without a CPU somewhere. So why the name? Well, let’s take a step back in history to how we did things a few decades ago (and how a lot of companies still work!).
The Olden Days
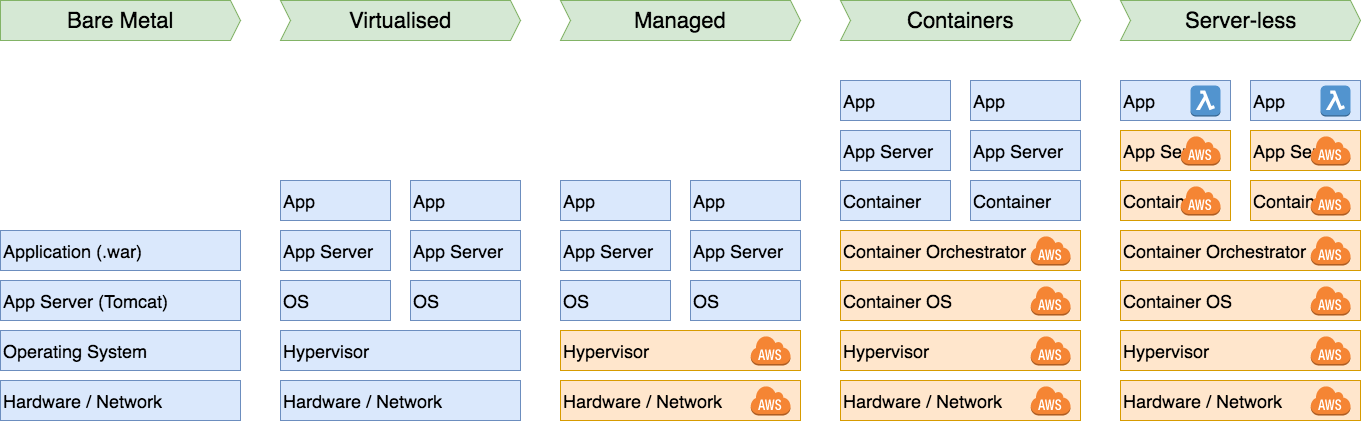
Let’s say it’s the year 1999 and we have a standard application stack looking somewhat like this:
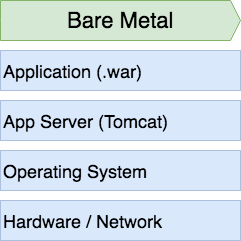
We have some networked hardware; a nice pizza box in our datacenter (or an old desktop under the SysAdmin’s desk), an operating system, an application server (Tomcat) and on top of that a Java application deployed for example via .war file. This is talking to another box close by that hosts our database.
This was back when we had typically a 1-to-1 relationship between a physical box and it’s task. So our application servers had hostnames based on solar bodies (luna, saturn) while our database servers used comic character names (superman, batman) and our web servers were called after mythological characters (odin, hera) and we had long lunch discussions on whether Thor should be a DB server or a web server.
When our SysAdmin told us "Marvin" was dead we knew we’d have to use IRC (Slack without the excessive memory use) for a while instead of e-mail. The SysAdmin probably had to pull it out of the rack, replace whatever part was 'broken', restore from backup what needed restoring and then turn it back on again. It was not uncommon to have your e-mail not function for a day.
Virtualisation
For a small company this might work but as you can imagine when you have a large company with thousands of servers this becomes hard to maintain. This is why a large bank for example could easily employ over a thousand sys-admins who were all responsible for their own group of servers. You had teams that were specialised in Active Directory servers while others were trying to keep your Oracle servers from catching on fire.
The next step was virtualisation; why run a single app server on a machine if you did not use all the capacity? It is wasteful. Virtualisation let us have a nice hypervisor layer in between so we could have different 'machines' on the same physical box. This was also the end of debates of naming hardware; we would soon favour multiple pieces of cheap commodity hardware over old big pieces of have metal. We started favouring horizontal scaling (more machines) over vertical scaling (faster machines). In general two pieces of hardware are cheaper than a single piece double as fast.
In addition; it abstracted away (to a certain extent) the physical hardware. You could have a team focus on network, another on storage, while an Oracle specialist would only need to focus on the application itself.
Economics were the main driver here:
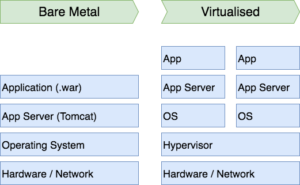
This now allows us to easily move virtual machines around. Want to start small with an app server and database on the same machine? Sure. You’re now growing and want to separate them? Simply move the database to a new machine and create a new app server VM on the first. An AD server breaks? Just move it to a spare.
Cloud Computing
Then "The Cloud" happened. What is the cloud? It’s basically just letting another company handle everything up to and including the hypervisor for you. You can create virtual machines; as many as you like. They take care of everything underneath. Economy of scale applies here: for a small company this means you don’t need to have your sole developer / sysadmin / hacker / in-charge-of-everything-with-a-powercord have to deal with network issues anymore. Instead this person can now focus on doing useful work. So "the cloud" is really just virtualisation where you outsource part of the work:
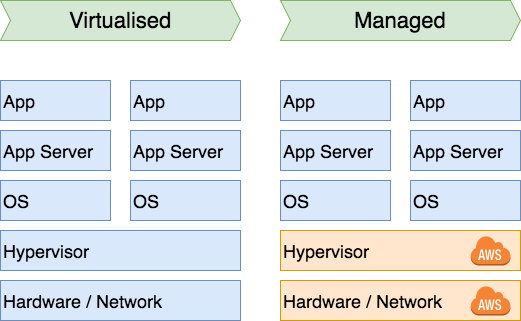
Another important factor of 'scale' that huge hosting companies like Amazon can get much better deals on hardware and software than most small to medium (and large) companies can. Only companies the size of Amazon or Google can convince companies like Microsoft that they should be able to bill a Microsoft Windows Server licence to you by the second. The same applies to hardware: there’s no way you can get it as cheap because an Amazon or Google buys servers by the thousands custom built to their specifications.
So now that they’re managing our infrastructure (IaaS), why not have them manage other stuff too? Want a database? Amazon can manage it for you. Want a queue? Sure. Load balancers? Got it! Act as a CDN? Got you covered! And not only are they created for you, they are also managed for you. So if you use Amazon RDS (a relational database of your choosing managed by Amazon) they handle all the patching for you, even if you use a master-slave setup. You won’t have to experiment with the new combination of the latest Postgres and the latest Linux patches because Amazon already did this for you.
Instead of hosting your own DNS server you can use Route 53. Instead of installing your own Cassandra you can use DynamoDB. Instead of creating your own CDN you can use CloudFront. Amazon has created an entire platform for you where you don’t have to worry about scale because they already solved these issues way before you needed to.
In addition: like Werner Vogels, CTO of Amazon says: "Everything fails all the time". At a large scale stuff breaks. Hard disks fail, network cards burn out, CPU’s fry, etcetera. It’s much easier and faster to automatically swap a virtual machine to a healthy piece of hardware than it is to find that particular machine, figure out what’s wrong, replace the part and turn it back on.
Cutting Edge: Container Orchestration
Now that you are running in the cloud where we can automate the creation and destruction of computing instances we can finally create awesome auto-scaling clusters. We don’t need to wait for another node for two weeks; we can have one spun up in two minutes based off a prebaked image. So we have an additional step in the evolution:
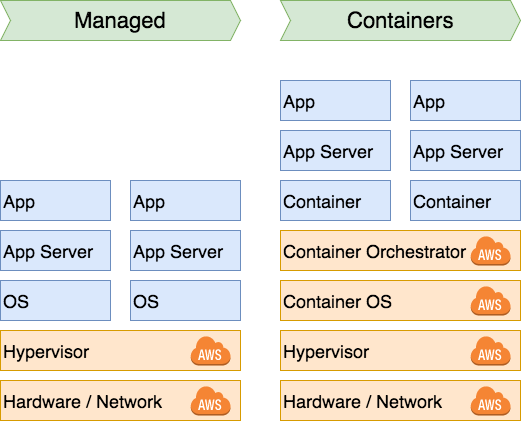
We’ve added another layer to the stack: the container OS (a lightweight OS designed to do nothing other than act as a Docker machine) and a container orchestrator. The orchestrator is in charge of deploying and scaling our application (at this stage probably microservices). While there is an added complexity that you need to deal with up front is is a complexity that is easy to automate. This is why microservices, containers and CI/CD go hand in hand.
You can go even one step further: since we scale on demand we can also just use cheap 'leftover' computing power. So for instance you can have a Kubernetes cluster with 3 permanent EC2 instances for the master nodes and have all the compute nodes be cheap AWS Spot instances. With Spot Fleet you can even instruct amazon to automatically keep a group of N spot instances alive. So you can automatically scale your number of Kubernetes deployments based on the health of a microservice. And you can automatically scale your number of instances in your Spot Fleet based on the compute demands of the cluster.
You can use your own cluster orchestrator like Kubernetes, Mesos or Docker Swarm but you can also let Amazon handle this for you though Amazon EC2 Container Service . Again one less thing to worry about.
I am personally a big fan of Kubernetes though. It’s very mature and seems to currently have 'won' the container orchestrating war.
Next step: Serverless
While incredibly cool and cutting edge: the scenario above, even if we use cloud services like DynamoDB and S3, would still require us to set up and maintain our own Kubernetes cluster with it’s own Docker registry. While it’s fun to set up, it still takes time. What if we could completely get rid of this?
This is what "serverless" means. As a software engineer your goal is not to create a cluster; the goal is to create software. What if we take this cluster of cheap compute power where we just deploy microservices in Docker containers one step further. What if we get rid of both the cluster and the deployment and scaling? We’d end up with this:
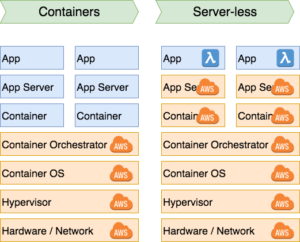
With AWS Lambda you are creating functions. Tiny services that just do one single thing. So instead of a 'users' micro service with controller methods for GET, POST, DELETE etc. you would get a GetUser lambda, a CreateUser lambda and a DeleteUser lambda which you then expose via an API-gateway.
What is neat about this is that AWS handles the application server and scaling for you. So if you do one thousand GetUser calls at the same time you will have one thousands little VMs running your GetUser code. AWS handles scaling the number of hot VMs up and down for you.
What is also neat is that lambda’s are composable. They are decoupled; a GetUser lambda just returns a User object. If you want to bind it to a GET request you will have to link it up to a GET route in the api-gateway. Other lambda’s can also call GetUser. Or you can use a message on a topic as a trigger. You can have it trigger when an S3 object gets created, deleted or updated. You can have a lambda trigger when a record in DynamoDB is changed. Or you can simply trigger it on a certain time.
And aside from having us spend less time on infrastructure or platform; Lambda’s are really incredibly cheap. On Amazon you get one million free calls a month. Why is this so cheap? These calls are short-lived. A Lambda can run a maximum of 5 minutes after which it is terminated. These VMs running these lambda’s can be spun up by Amazon anywhere they want (within your region of course). So it allows them to utilise hardware whenever and wherever they want.
So to show the complete picture
So what will the next steps be? Hard to say. My guess is that we are first going to see more abstraction before we are going to take steps into offloading more work. What that abstraction will be is hard to predict however.
A silver bullet?
No, definitely not. While lambda’s are incredibly cool they are just an architectural pattern. And while many patterns have become popular (microservice architectures being a great example) they tend to all come with trade-offs.
Serverless is microservices taken to the extreme. With the added benefit of not having to even manage your own container orchestrator. But like microservices there are downsides. How are you going to handle versioning? Shared libraries? You can’t really do transactions anymore, do we need those?
Also it is again a new form of dealing with software that requires you to be in a slightly different mindset. They are not applications anymore. A microservice while generally stateless is still something that is expected to run for an undefined amount of time; multiple hours at least. A lambda can’t run for more than 5 minutes and be default has a 2 second timeout. So instead of having a single service handling 20 requests in parallel you can have 20 tiny services running in parallel (lambda’s) handling 1 request.
While this does force you to work stateless it also makes some things much easier to implement. For example if you trigger a Lambda based on an SNS (a pub-sub mechanism) message AWS will do a certain amount of retries for you if your lambda crashes for some reason.
Fortunately it is possible to mix-and-match these architectures. If you want to have both a few EC2 instances running a monolithic API together with a swarm of Lambda functions doing everything else? Sure! While by default a lambda is not connected to your own VPC that is basically a matter of checking a box.
Conclusion
Serverless is not a revolution but simply an evolution of improvements in the last few decades. It definitely can bring efficiency and economical benefits to your organization, but it will also require your development team to learn a new form of architecture.
I hope the text and graphics show that serverless is not a fad or a hype. It’s simply the next evolutionary step of letting others do the work you don’t want to be doing yourself. But what about the Amazon vendor lock-in? Want to go serverless on a self-managed cluster? OpenFaaS has you covered there; you should definitely check it out. It’s Functions as a Service running on top of any Kubernetes installation.
In the next post (coming soon!) in this series I am going to show how to get started with Java Lambda’s on Amazon.
