Microservices: A workshop by Sam Newman
Today I’ve been working exactly minus 23 days at JDriven. So as you might expect, officially I’ll be starting there at the first of July. For my new employer, this is no reason at all not to invite you on the seminars they provide for their people, so yes this proved as well there is a reason to make this next step into choosing for JDriven. So last Thursday there I headed to headquarters at Nieuwegein for a full day workshop about Microservices, given by nobody else than Sam Newman!
Sam Newman
Okay, for the ones who don’t know, he is the author of the books ’Building Microservices’, ’Lightweight Systems for Realtime Monitoring’, and the forthcoming book ’Monolith to Microservices’, all published by O’Reilly. He’s also known being the co-creator of the Lego XP Game.
The workshop
Not knowing what to expect exactly, I went in open minded and just let it come over me. The approach was simple enough, and I liked the pragmatic way of setting it up. He had the day broken up into 4 workshops, with enough time to take a break and have a wonderful lunch that was organised by JDriven.
He had done no preparation on the topics, so the first part he did was making a round through the audience to collect the topics we wanted to be handled.
The topics
I was not able to be there for the whole day, so sadly I missed the last workshop. Anyway there was a great deal to learn, and the topics where interesting, I’ll share what I’ve seen, and even in that context, I’m not able to cover it all, then this read would be way to long!
1. When (not) to use a microservices architecture
Microservices are hot and hip. So you often hear the CIO’s from the bigger companies telling that they’re into Microservices. When you’re actually deep-diving into the why, the probably don’t have a real answer.
When you want to move to an microservices architecture, one should definitely start by asking yourself what you want to achieve, and start by wondering if it would fix the real problem you have.
Microservices are no golden egg solution that solve any problem there is, you also don’t need them to actually grow and be successful. Large companies that did not start using them are for example Salesforce or Atlassian.
Sam would definitely not advice startups to directly use a microservices architecture, and for larger companies, he’d would say that you have to slowly dial the switch, and learn on the way. Biggest concern is that there is a lot to learn, and to consider, so avoid getting into a big bang release on creating a brand new architecture, that on the day that you roll it out won’t perform, have strange errors or just does not work at all. The cognitive burden must be addressed, and evolution needs to be balanced agains system or cognitive overload.
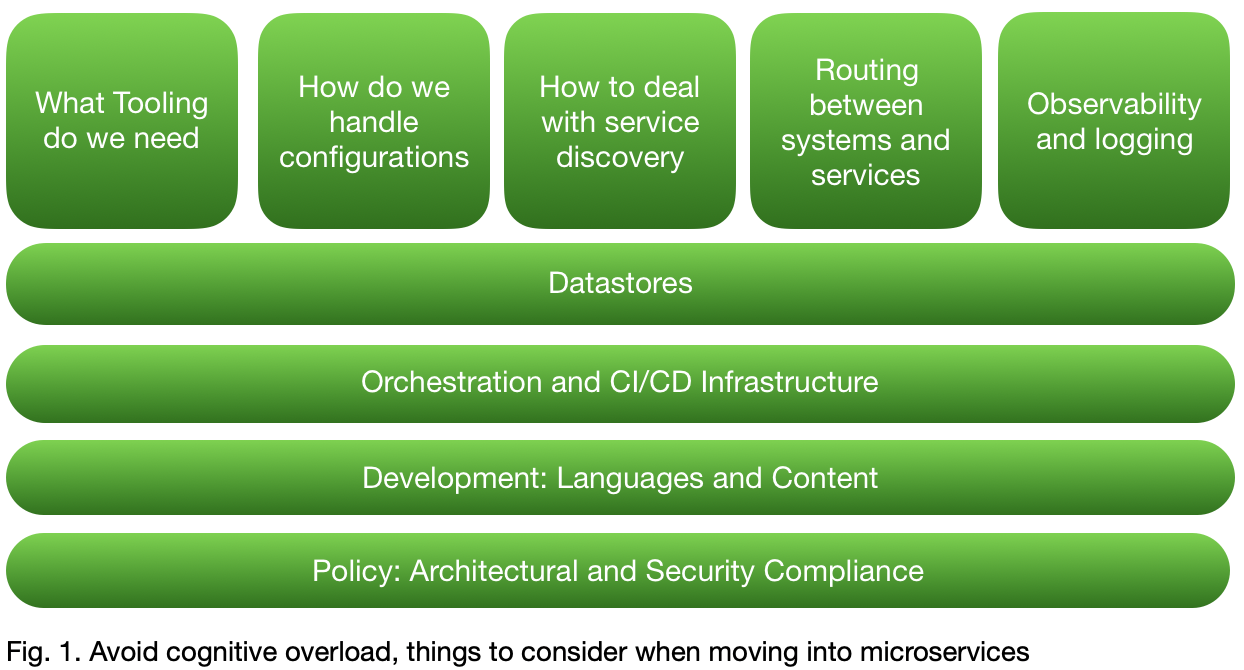
2. How big should a microservice be? How to divide responsibilities and how to deal with own or shared databases.
Sam is a great advocate of Domain Driven Design. He did a great talk about bounded context, as it is a central pattern in Domain Driven Design. It lays focus on designing software based on the underlying business domain. To help development teams and business teams to understand each other a bit better, he suggests to create your ubiquitous language, so anyone within the context of a business domain understands you what you mean by a ‘customer’, or ‘visitor’.
When you want to want to set the boundaries around your service, a great way of setting responsibilities can be done using event-storming. Sams suggested us to make sure the developers need to listen here, and let the business people do the talking. Else you’d end up with a new model, that describes the functionality and software that is already there, and you want to describe business processes here.
Then of course the question about sizing. In short, to his opinion the answer is: It depends. Small is a relative term, and when you just start creating microservices, you might need to give another answer to that question then when you’ve got hundreds of them. Again he gets into the acronym of slowly turning the dial.

So it all boils down to ‘just big enough’ to make sure they do what is needed. He also talked about the coupling in context of microservices. He distinguishes 3 types of coupling, Domain coupling, Implementation coupling and Temporal coupling. It would go to far to go into detail here, but like in the book ‘The pragmatic programmer’, chapter 2 about Orthogonality: Avoid tight coupling!
3. How to deal with service communication, latency, API versioning, Type safe communication using Schemas
As for the last part about coupling, he also advices to create well-designed service interfaces, just as OO developers do using encapsulation, a microservice should be treated as a black box, so you should, for example never connect to its database directly.
Trying to think ‘outside-in’ in your design. Your interface should be stable, and should not change. So think about what your service consumers need from you, design your interface (contract) and then code your models and underlaying databases.
It would as well be a good idea to use contracts for interfaces for example JSON schema, Swagger (though it was designed for documenting purposes in the first place), WSDL or gRPC.
4. How to deal with data duplication, consistency, robustness and caching
As told, an interface should be hard to change. Keep in mind that things could easily go wrong if your interface suddenly has some structural (needs type safety) or semantic (needs testing) changes. Your consuming service could suddenly stop working!
Then there is the case on performance, what do we do on performance? Yes! We’re going to implement a caching layer. So service A who consumes data from service B is going to create some caching to avoid extra latency and calls to service B. But the team working on their microservice got the complaint about speed, so implemented a reverse caching proxy on their interface. After some testing they found that they relied on service C, there was the actual bottleneck, so they implemented some internal caches there as well.
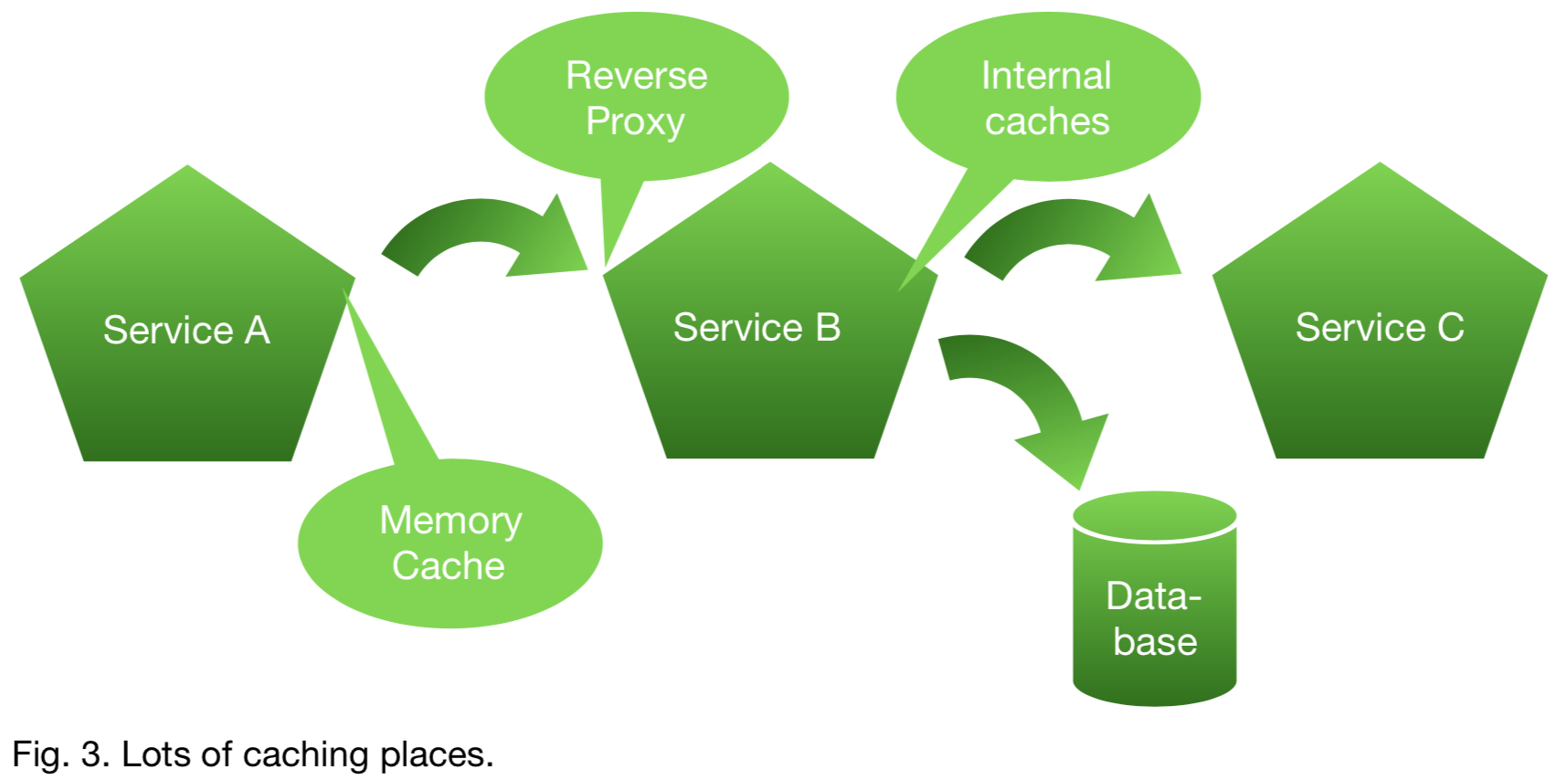
As you might think here, how on earth do I make sure that service A has the right information? When the info needed from service B (that originates in C), has changed, each cache can have its own TTL, so even when the first caches are invalidated, there might still be a third giving the wrong data back. This would not be a design we would like :)
So yes, caching could reduce latency, but think well before you implement it. Where to implement it, can we use conditional tags (e-tags), make sure that caching is implemented as read-only. Etc.
Next, we could think on event propagation to make sure caches are invalidated at the proper time, and use data locking where needed.
In general it would be a good idea to avoid long call chains.
Another thing that might help on latency and robust system is using good message brokers. Keep in mind that good brokers like Kafka do have a lot of documentation, we don’t tend to read. If it’s about message ordering, deliver messages one etc. there is a lot of reading on how to use it to do.
Some other small tips when you’re going to build microservices: Implement correlation ID’s Ask the team to implement aggregated logging, if they’re not able to do it, they’re not ready for implementing microservices.
References:
- Domain driven design - Eric Evans (2004)
- Domain driven design distilled - Vaughn Veron
- Event storming - Zio Brando
- Rest in practice
- Glory of rest (maturity model) - Fowler
Some nice reads:
Byzantine generals problem
sagas
