Containerization: Is it the solution that solves your DevOps issues?
Nowadays you can’t walk into an IT department without hearing discussions about containerization.
Should we move to OpenStack or OpenShift?
Do we want to use Pivotal Cloud Foundry?
What about Docker Swarm or Kubernetes?
How to integrate our new kubernetes cluster into our CI/CD pipelines?
Keep in mind that DevOps using unmanaged infra adds an extra layer of complexity to the development teams.
In the end, you might save money on an Ops team, but the tasks still need to be executed, leaving the work for the development team.
As an example, when you create some new code, make a pull-request, the CI/CD pipeline kicks in to automatically build your code, perform (unit) tests, deploy to the next environment, etc.
When an error occurs, the pull request would be rejected, leaving the developer to fix any possible issues, even infra.
What happens when a new base image is being delivered due to the fact that there is a security fix in the OS? Again, the CI/CD pipeline would be triggered, since source code and (Docker) image go hand in hand (e.g. on Kubernetes clusters). If the build fails, who would be responsible to fix the package? We can’t leave the production environment without that important security fix, can we? Time to dive a bit into containerization.
About Containerization
First some background information about Containerization.
Containerization is an alternative to full virtualisation.
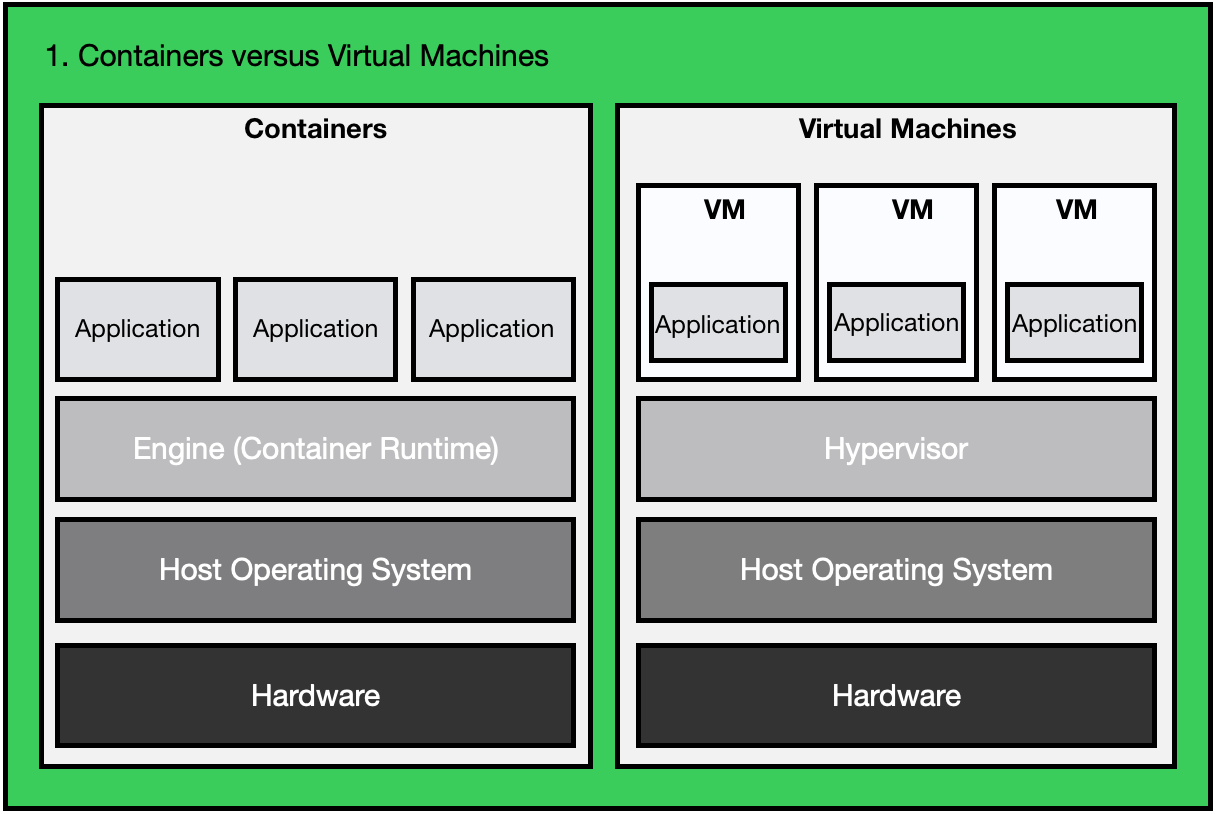
Containers and VMs are often compared, since both allow multiple types of software to be run in contained environments.
Containers are an abstraction of the application layer, each container simulates a different software application layer.
It involves encapsulating an application in a container using its own operating system, but it can share the underlying engine of the host.
In other words: A container is a standard unit of software that packages up code and all dependencies to be able to run the application standalone.
Virtual machines are an abstraction of the hardware layer, so every VM simulates a full physical machine that can run your software.
VM technology can use one physical server to run many virtual machines, but each VM has its own copy of the full Operating System, applications and related files, libraries and dependencies.
Containers on the other hand package code and dependencies together.
Multiple containers are able to share the host OS Kernel with other containers, but they are running as isolated processes in their own user space.
This makes them more lightweight and take up less space than VM’s.
The picture below gives an overview of the differences between VM’s and containerized systems.
Some different solutions
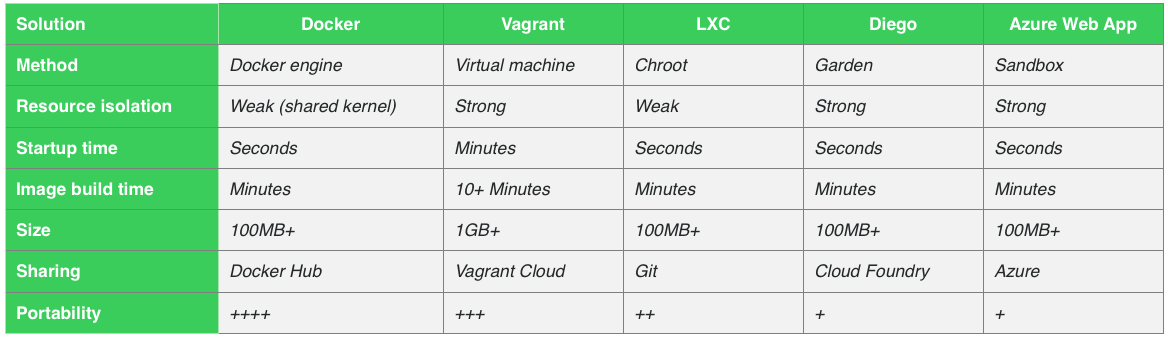
Within the development community, there are quite a few well known options that are being used to be able to containerize your application.
In the table below, you’ll find a short comparison between the different options.
You’ll notice that I’ve mentioned Vagrant as well, and even though Vagrant does not comply to the definition of delivering containerization (as it is based on scripting VM images), it’s a popular alternative. It is also a nice way to show some differences between VM solutions and real containers.
Why containerization / What does it solve?
In traditional software development, the code that’s being developed on one environment (e.g. your development environment), often runs with bugs or errors when it’s being deployed in another environment, like Test, Acceptance or Production.
Developers try to solve this issue by using containers, since they are able to deliver a solution to the problem of how to get software to run reliably when moved from one environment to another by using the concept of immutable hosts.
Only the configuration decides the state of the application. In development this is tightly bound to the CI/CD pipeline on an automated DTAP street.
Since the image, libraries and application are bundled together, you won’t get the common phrase: “But it works on _ (you fill in the blanks) environment”. If your app is not working in ‘the next stage’, it’s most likely a configuration issue. So how do containers solve the issue exactly? Looking back at the explanation of what a container is, all your dependencies, runtime environment, libraries and configuration are bundled in one package. Since it runs against an underlying abstraction layer, you do not have to worry about infrastructure or OS differences. Only the configuration (e.g. connection strings) may differ, so if your tests are okay in Dev or Test, you know any possible issues are not software related.
Why then use containers instead of VMs?
With virtualisation, your package is a virtual machine, and it includes an entire operating system as well as the application.
A server running three virtual machines would have its own OS, a hypervisor and three separate operating systems running on top of it, where the same solution in a containerized solution would run on a single OS.
They share the same system kernel, but have their own mount (disk-space).
Hence, a containerized solution is way more portable and light-weight.
Another benefit is that containerization offers better modularity. Using containers, you can split your application more easily into modules (e.g. back-end, database, front-end) to use a microservices approach.
Docker
When talking or reading about containers, you’re probably thinking about Docker.
Docker is almost seen as a synonym to containers, as it has become the de facto standard.
As seen in the comparison table, you’ll notice that there are a lot of other possible options.
Also it’s not new.
On Linux we know the use of jails or sandboxes and chroot for over 10 years now!
One of the main advantages when you use Docker is that you can be sure that the same application image will be able to run on different platforms. You will be able to switch between different providers (or private servers) without having to modify your app. It does not remove the need to deploy your app to a cloud provider however. Cloud providers provide an infrastructure or a platform for you to deploy your apps to.
Some pitfalls, or when not to use Docker:
-
When you need persistent data storage, a solution using Docker might be complicated. By design, all of the data inside a container is removed when it is shut down, so you have to save it in another place. E.g. saving states in CosmosDB, or in memory storage in Redis.
-
When it comes to stability, keep in mind that Docker is still based on a lot of unstable APIs and tools. Some DevOps have reported at least one kernel crash per month in production.
-
Docker developers break their own API regularly, so extra development time is needed to adhere to the changes.
-
Disk speed might be low. There are several benchmarks about system call overhead for Docker, and normally Docker performs well. When it comes to IO overhead in the form of file system and network, the overhead can be quite high.
-
Managing a huge amount of containers may be challenging, especially when it comes to clustering containers. This is why you need an orchestration layer like Kubernetes (see next chapter).
-
Not all applications do benefit from containers. In general, only applications that are designed to run as a set of discrete microservices or modules have a real advantage of using containers, but still you could use it to lift and shift your old apps to move them into a cloud environment.
-
The Docker ecosystem is fractured. Although the core Docker platform is open source, some container products don’t work with other ones.
-
When performance is one of your important non-functional requirements, be aware of the fact that although containers are more lightweight and portable than VMs, it’s still a form of virtualization. The underlying resources are not always as much available as one might think and can’t be guaranteed. So if performance is mission critical for your app or organisation, considering a bare-metal approach is not a bad idea.
-
The underlying OS (Kernel) needs to be maintained. If you have a security issue in the kernel, all containers using that kernel have the same security issue.
Base images
A base image is in essence the user-space of the os packaged up and shipped around.
Mostly being referred to as the OCI/Docker image.
It contains libraries as glibc, zlib and language runtimes as Python, Node.js and Bash.
It is important to think about architecture, security, performance, size, ease of use, support and scalability when choosing your base image.
Example of different base images from commercial to full open source.

(*1) wiki.alpinelinux.org
(*2) www.securityweek.com
-
Keep in mind that even though Alpine is small as base image, most of the needed features to run your application still need to be installed. For example, after adding JDK, Tomcat and reverse proxy, your base image now grows to the same 120MB as the Ubuntu image has.
-
Security-wise, third party software that scans against CVE databases, cannot do that for Alpine
-
Using Alpine, you don’t have a glibc library, so you might be dependent on (obscure?) third party packages that are installed as dependencies of that package you need to run your software.
Orchestration
Having a few applications running on about 10 containers, administration is not that much of an issue.
When you get into a more complex environment, things are getting more complicated. When you scale up, need automated deployment, container management, auto-scaling, monitoring and availability becomes essential.
This is where container orchestration kicks in.
Container orchestration manages the lifecycle of a container. Teams use container orchestration to automate tasks like:
-
Auto-scaling (horizontal / vertical) of containers
-
Allocate (shared) resources between containers
-
Load balancing
-
Health monitoring
-
Configuring state (e.g. ACC/Staging/PRD)
-
Deployment of (new) containers
-
Exposure or hiding containers from the outer world
-
Applying security rules
-
Service discovery (between containers and services)
The following solutions are well known as cloud-native orchestration solutions:

As you probably understand, there are more solutions than mentioned above, and we could fill a lot of posts on orchestration solutions.
Sources:
