A day in the life of DevOps
No qualms with CALMS
DevOps is the idea, that the concerns and interests of developers and those of operations are better served when they aren’t addressed in isolation as individual silos, but in unison. As a result, the whole organization that depends on both ends up being more agile and more stable

CALMS
This simple idea is in itself a powerful thing to guide organizational structuring and decisionmaking processes. To give it more body still, it’s often implemented by a “framework” called CALMS. This acronym that captures five capabilities that an organization should strive for, in order to achieve that state of DevOpsness:
-
Culture
-
Automation
-
Lean
-
Measurement
-
Sharing
Of these five, culture is probably the least tangible, in the sense that you probably know whether you’re in a culture that supports DevOps, but it’s harder to determine what it is that makes it that way. Whenever you see Jez Humble give a presentation on the matter, you’ll likely see a slide like the one below, showing a situation where DevOps culture is clearly absent.
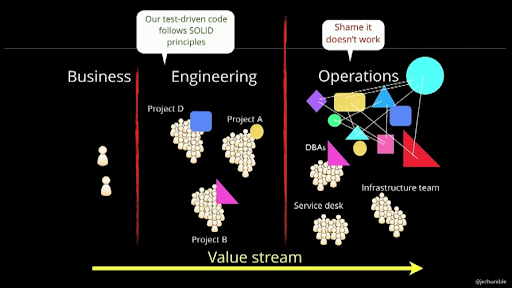
This slide can be used to explain many problems related to Continuous Delivery, but above all, it shows a cultural difference: Developers follow agile, SOLID, TDD and other best practices to constantly deliver new software, but do not share the view of the resulting software landscape that operations has, nor the problems that arise from it.
I sadly don’t remember who to attribute the following insight to, but I once learned that culture is defined by the people’s actions and responses. To give an example of this, I will share something that happened in my work recently.
A day in the life
My team builds applications that deploy to production several times a day on a cloud container platform. We have some ability to make use of cloud native components, but mostly this is not something that requires our constant attention, and the concern for cloud platform management is placed in the hands of a separate team with the required expertise. They also take care of first line technical support.
Every now and then, there are operational hiccups, and I’m proud to say we often catch and solve incidents that might affect the user experience of our customers before the customer support service even hears about them.
Some factors that contribute to this success are
-
short communication lines between the ops team and the development team;
-
a shared sense of responsibility for ensuring good customer experience;
-
the ability to roll out/forward fixes through our delivery pipelines quickly.
When something does slip past us, we blamelessly evaluate how that could happen together, thanks to a mindset of continuous improvement, and decide whether to adjust or expand our monitors and alerts.
We use DataDog to monitor operation, using alerts on things like error log anomalies and running constant synthetics tests to ensure vital functionalities are available. Alerts are sent to dedicated Slack channels that developers and operations engineers listen in on, and everyone shares in a culture where people take those alerts seriously. Alerts are also sent to OpsGenie, which notifies operations on out-of-office hours. Given the way our applications and infrastructure have been performing, and given how our ops team has been able to deal with most incidents, developers have been blissfully exempt from having to share in that duty, even though their contact details are known and they’re only a phone call away.
For the most part, every development team takes care of their own monitors, tests and alerts.
One day, I wrote a new synthetics test that validates that a customer has access to crucial functionality when they reach a specific point in their journey. I added the OpsGenie notification as a matter of habit, copying and adjusting the notification text from another test I’d made before. In essence, it looked roughly (I’ve removed actual project/function/team names) like this:
Journey X point Y: the test, to see if user interface component Q is available, is failing.
@opsgenie-Opsgenie @slack-prod-urgent @slack-myteam-notifyWhile doing a testrun, the test failed because I had made a typo, which I noticed when the alert popped up in the Slack notification channel #slack-myteam-notify.
I fixed the test and was about to proceed with other work, when a colleague from the ops team approached me.
Ops: “Can I make a suggestion?”
Me: “What?”
Ops: “Please take a look at this notification text that I took from another monitor we made recently. Helpful messages like this help our standby colleagues if the alert is sent to OpsGenie during standby.”
Me: “Ok. The thing is that when this one fails, the course of action isn’t so evident as in your example. It would require us to look at several things, and possibly contact an external party. Shall I remove the OpsGenie notification?”
Ops: “It wouldn’t make sense to not inform us if this is an urgent event that requires a solution. Can you add escalation suggestions?”
Me: “I can do that.”
This short interaction forced me to reconsider what I’d want to know if I was notified of this urgent alert out of the blue at 4 in the morning, without the context from which the necessity for the test was born. Even though it was a complicated problem that might require exploring several avenues, I thought about the most likely culprits, where to start looking for them, which signs to pay attention to, and who to contact for further escalation.
I changed the notification text to something like this:
Journey X point Y: the test, to see if user interface component Q is available, is failing.
{{#is_alert}}
Customers may not be able to complete X, which is a crucial functionality.
Issue most likely lies with ExternalParty API.
Check for error pattern Z in errorlogs of microservice A, B or C.
Also check container platform dashboard to see if A or C have successfully started.
Contact details for ExternalParty available in MyTeam contactlist.
{{/#is_alert}}
{{#is_alert_recovery}}
Interface component Q is available again. Customers should be able to complete X once more.
{{/is_alert_recovery}}
@opsgenie-Opsgenie @slack-prod-urgent @slack-myteam-notifyOf course component Q, error pattern Z, X, ExternalParty and microservice A, B or C and MyTeam were actual values that I’ve left out of this example.
Information in a message like this is effectively documentation, meaning it needs to be kept up to date in accordance with the actual implementation. This is why on the one hand, it may be better to refer to a pattern than an exact log, and to refer to a contactlist than to add exact contactdetails, to avoid having to update it with every change.
On the other hand, it may be better to have a test like this configured as code in the same place that is most likely to be the cause of a change to the test contents. For example: the repository for component Q mentioned above would be a good candidate to also hold the code that configures the corresponding UI test in DataDog, so that when anything changes for component Q, you’d implement those changes in the same place that configures the monitors and alerts for correct functioning of component Q.
My operations colleague reviewed the new notification text, and gave his okay. Soon after, he got back to me to verify other assumptions he had been making about functional dependencies between these and other applications. As we talked, I realized there were other monitors and alerts that could easily be made more informative to help give more functional and technical context to aid root cause analysis and troubleshooting efforts. Just because they’d never complained about it, I had assumed they were perfectly fine. And so we’ve set out to improve these as well, in the process helping the ops team make more functional sense of the software landscape.
Takeaway
Why did I share this story?

I hope you’ve noticed the story contains things you would call
-
continuous improvement
-
blameless post-mortem
-
sharing
-
automation
-
feedback loops
-
reducing waste
-
infrastructure as code
A story says more about the value of these aspects of a DevOps culture than merely mentioning a list of abstract platitudes can.
